Agent
大模型Agent是一种基于大型语言模型(LLM)的智能体,具备环境感知、自主理解、决策制定及执行行动的能力。它能够模拟独立思考过程,灵活调用各类工具,逐步达成预设目标。
一般架构
大模型 Agent 由四个关键部分组成:
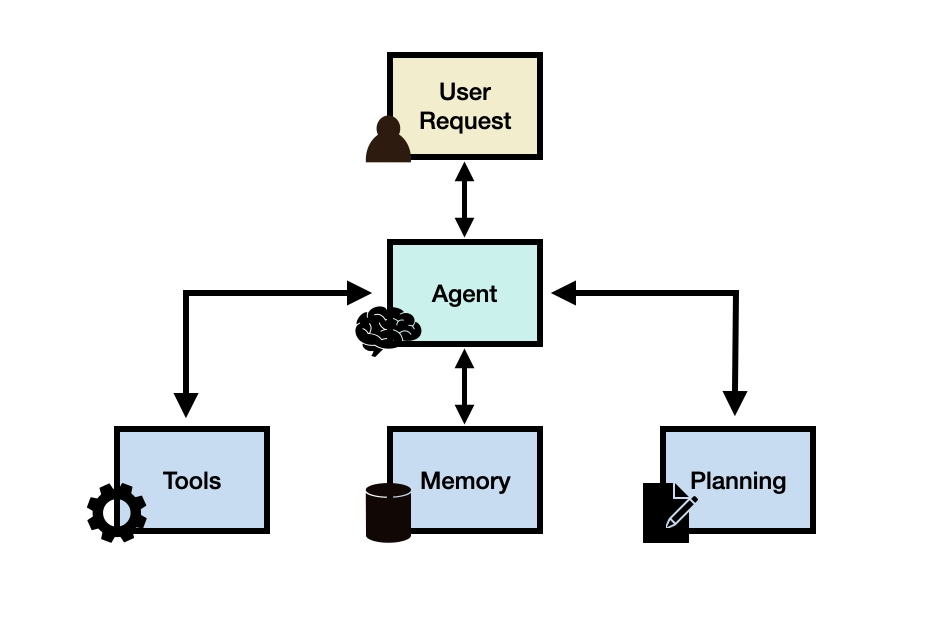
- 规划(Planning):负责拆解复杂任务为可执行的子任务,并评估执行策略。通过大模型提示工程(如ReAct、CoT推理模式)实现,使Agent能够精准拆解任务,分步解决。
- 记忆(Memory):包括短期记忆和长期记忆。短期记忆用于存储会话上下文,支持多轮对话;长期记忆则存储用户特征、业务数据等,通常通过向量数据库等技术实现快速存取。
- 工具(Tools):是Agent感知环境、执行决策的辅助手段,如API调用、插件扩展等。通过接入外部工具(如API、插件)扩展Agent的能力。
- 行动(Action):将规划与记忆转化为具体输出的过程,包括与外部环境的互动或工具调用。
另一种架构:
控制端:Brain
感知端:Perception
行动端:Action
AutoGPT(Prompt 工程)
在prompt层面,通过更好的提示词来激发模型的能力,把更多原先需要通过代码来实现的流程”硬逻辑”转化为模型自动生成的”动态逻辑”。
提示词框架
-
Constraints & Resources
在这里告诉了模型你自己的各种局限性,例如模型的输入 context size 有限制,所以你需要把重要的信息保存到文件里。 所有的知识只更新到训练数据的截止日期。模型可以通 过网络搜索来获取更多时效性的外部信息。
-
Commands
在commands也就是各类工具的选择上,这里给出的选项非常丰富。可以分为几大类commands,包括搜索、浏览网页相关,启动其它的 GPT agent,文件读写操作,代码生成与执行等。
-
Performance Evaluation
这里给出了模型整体思考流程的指导原则,分为了几个具体维度,包括对自己的能力与行为的匹配进行review,大局观与自我反思,结合长期记忆对决策动作进行优化,以及尽可能高效率地用较少的动作来完成任务。这个思考逻辑也非常符合人类的思考,决策与反馈迭代的过程。
-
Response
格式的限定:对前面思维指导原则的具体操作规范说明。 下一轮具体的操作
缺点
-
需要参数大的模型
-
迁移性差,不同模型有对应不同的提示词
BabyAGI
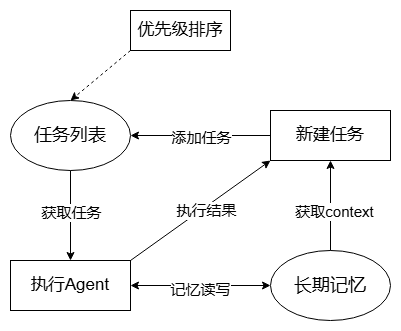
- 把复杂的大模型通过大模型分解成多个子任务
- 大模型多次执行子任务
- 得到最终结果
HuggingGPT
HuggingGPT,利用 LLM(例如 ChatGPT)连接机器学习社区中的各种人工智能模型(例如 HuggingFace)来解决人工智能任务的系统。
工作流程

HuggingGPT 的工作可以分为四个阶段:
- 任务规划(Task Planning):使用 ChatGPT 分析用户请求,将其分解为多个子任务,规划任务顺序和依赖关系。
- 模型选择(Model Selection):对于子任务,根据Hugging Face中的函数描述选择模型,并用选中的模型执行AI任务
- 任务执行(Task Execution):每个专家模型执行所分配的子任务,返回执行结果。
- 响应生成(Response Generation):最后由 ChatGPT 集成所有专家模型的结果,并为用户生成答案。
缺点
- 链路过长,其中一个环境出现问题,后续都会出现问题
LlamaIndex
辅助模型记忆力,把数据和知识以不同的结构存储起来,然后通过不同检索方式获取知识
接收输入数据并为其构建索引,随后会使用该索引来回答与输入数据相关的任何问题。所有索引类型都由“节点”组成,节点代表了文档中的一段文本。
核心:索引结构的集合
概念
- Node(节点):即一段文本(Chunk of Text),LlamaIndex读取文档(documents)对象,并将其解析/划分(parse/chunk)成 Node 节点对象,构建起索引。
- Response Synthesis(回复合成):LlamaIndex 进行检索节点并响应回复合成,不同的模式有不同的响应模式(比如向量查询、树形查询就不同),合成不同的扩充Prompt。
索引方式
-
列表索引(List Index):Node顺序存储。关键字检索
Llamalndex会使用每个节点的文本进行查询,并根据附加数据逐步优化答案。
-
向量存储索引(Vector Store Index):每个Node一个向量,将节点存储为向量嵌入,而 Llamalndex 可以支持这些向量 embedding 进行本地存储或使用专门的向量数据库(如 Milvus)存储。向量检索
-
树索引(Tree Index):树形Node,从树根向叶子向下查询,可单边查询,或者双边查询合并。
-
关键词索引(Keyword Table Index):每个Node有很多个Keywords链接,通过查Keyword能查询对应Node。
-
知识图谱索引(Knowledge Graph Index):在一组文档上提取形式为(主语、谓语、宾语)的知识三元组来构建索引
TOT(Tree of Thought)
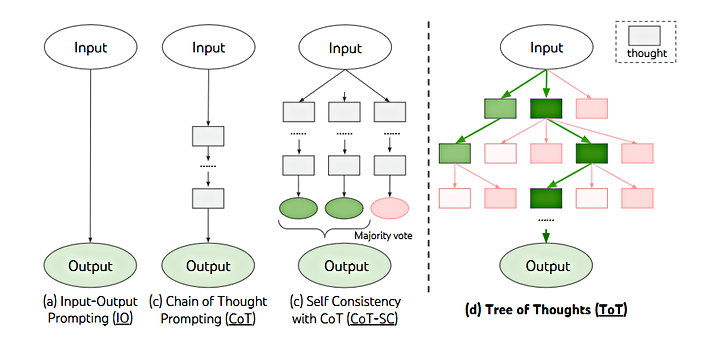
- IO:直接问答
- CoT:思维链
- CoT-SC:思维链+投票机制
- ToT:搜索,评估,回溯,树状
-
分解有可能解决问题的方案
-
评估分解的步骤,选择最有可能的方案
prompt 设计模式
- CoT prompt,在给出指令的过程中,同时也给出执行任务过程的拆解或者样例
- “自我审视”,提醒模型在产出结果之前,先自我审视一下,看看是否有更好的方案。也可以拿到结果后再调用一下模型强制审视一下。比如 AutoGPT里的 “Constructively self-criticize your big-picture behavior constantly”
- 分而治之,越是具体的context 和目标,模型往往完成得越好。所以把任务拆细再来应用模型,往往比让它一次性把整个任务做完效果要好。利用外部工具,嵌套agent等也都是这个角度,也是CoT的自然延伸。
- 先计划,居执行。BabyAGl,HuggingGPT 和 Generative Agents 都应用了这个模式。也可以扩展这个模式,例如在计划阶段让模型主动来提出问题,澄清目标,或者给出一些可能的方案,再由人工 review 来进行确认或者给出反馈,减少目标偏离的可能。
- 记忆系统,包括短期记忆和长期记忆的存储、加工和提取等。这个模式同样在几乎所有的 agent 项目里都有应用,也是目前能体现一些模型的实时学习能力的方案。